![[自媒體經營] AI 辨識更準確!快速為影片上字幕](https://make9.tw/wp-content/uploads/open-ai-whisper-cover2.jpg)
剪映可以語音辨識一鍵自動上字幕很久了,但直到最近 Whisper 這款跟 ChatGPT 師出同門來自 OpenAI 的語音辨識 AI 橫空出世。辨識率、準確率都更高!且 Whisper 能下載在自己電腦上執行不需仰賴網路將檔案上傳到主機去辨識,更加安全後我才第一次想嘗試為影片上字幕。
內容索引
Whisper 語音辨識上字幕優缺點
優點:
- 支援繁體中文,不須簡轉繁
- 在自己電腦上運行更安全、不怕服務倒閉、突然收費
- OPEN AI 出品、程式碼公開安全有保障
- 語音辨識準確率為目前市面可見最高
缺點:
- 需仰賴自己的電腦主機運行
- 如果沒有顯卡加速,只靠 CPU 跑速度會很慢
- 只支援 NVDIA 顯卡加速(GPU CUDA)
- 需使用終端機下指令(後面會分享使用介面方式)
下方還會分享有人拿 Whisper 的核心功能改成 GUI 介面(就是像我們一般用的程式,有操作介面點選),不但操作容易,效能要求還更低、運行速度更快!電腦效能不夠、使用內顯、或用 AMD 顯卡的可以嘗試看看。
影片:OpenAI 一鍵生成影片字幕 ChatGPT 同門 Whisper 語音辨識手把手教學
安裝與使用 OpenAI / Whisper 語音辨識產生字幕
起始
打開終端機 Terminal
終端機(Terminal),也有人稱為命令提示字元,就是電腦上那個黑色正方型視窗,只能用來輸入指令像是電影裡駭客在用的東西。
Windows 上打開 -> Win鍵 + R -> 輸入 cmd 按下確定。
Win鍵就是你鍵盤上有一個 windows 符號的那顆鍵,通常在 Ctrl 右邊有一顆。
步驟 1
安裝 Python
有些人電腦裡可能已經有 python 了,可以輸入下列指令測試:
python --version如果電腦已經有安裝 Python 它會返回版本號,如果為 3.7 版本以上可以不用另外安裝。
Whisper 官方宣告支援環境為 Python 3.7.x ~ 3.10.x 版本。
官方是使用 python 3.9.9 來測試 Whisper,我自己是安裝 3.10.7 的較新版本也無問題
步驟 2
安裝 FFmpeg
官網 -> Download -> windows -> gyan.dev -> release builds -> ffmpeg-release-full.7z(就是下載 full 的版本)
https://www.gyan.dev/ffmpeg/builds/(直接點擊連結前往比較快)
找個地方解壓縮,之後資料夾路徑要新增到環境變數 path 裡
資料夾放哪裡?
範例中是放在 Program Files,其實直接放 AI 資料夾也是可以
環境變數如何新增?
點入 bin 將資料夾路徑複製
[圖片]
EX:C:\Program Files\ffmpeg\bin
win + S 搜尋環境變數 -> 編輯系統環境變數 -> 最下方的環境變數點按鈕擊進去 -> 「系統變數」中找到「Path」,點擊兩下、按下「新增」並將剛剛複製的路徑 C:\Program Files\ffmpeg\bin 貼上後確定保存即可。
測試有無正確設定 FFmpeg
ffmpeg -version步驟 3
創建專案資料夾
找一個地方創建資料夾(我是直接在桌面創建一個 AI 資料夾、底下新增一個 Whisper 資料夾)
然後直接在 Wisper 資料夾上的路徑輸入 cmd
win 就會直接開啟一個終端機,已經在那個資料夾的路徑
在資料夾下創建虛擬環境
python -m venv .\venv進入虛擬環境(在該資料夾底下輸入)
venv\Scripts\activate如果看到前面多了(venv)就表示成功進入虛擬環境
步驟 4
安裝 openai/whisper
輸入指令安裝 Whisper:
pip install -U openai-whisper驗證有無安裝成功 & 查詢 Whisper 指令
whisper --help步驟 5
使用 Whisper 轉出字幕
用以下指令執行完成後,就會再聲檔旁邊看到轉出的字幕,有常見的 .txt、.srt 還有 .json、.vtt、.tsv 等字幕檔案。
其中時間較對其實很精準,可以把錯字修改完成後直接匯入 Youtube 做為 cc 字幕使用,或匯入你自己習慣的剪輯軟體。如果要求更精準的斷行,一樣可以用 .txt 搭配 oTranscribe 處理後,再用剪映來做文字的自動匹配,如果文字超過剪映自動匹配的 5,000 字,可以分段辨識後,再用 SrtEdit 來做 srt 檔案的合併。
whisper 指令:
whisper [音檔] --language [指定語言] --model [使用模型] --device [CPU或顯卡]- audio file 音檔
- 支援 mp3, flac, wav
- language 語言
- 支援世界大多流行語言包含繁中,英、日、韓文等
- model 語言模型
- 依小至大提供:tiny、base、small、medium、large。
- device 硬體
- 只支援 NVDIA 顯卡加速,輸入 CUDA。反之輸入 CPU 使用 CPU 執行。
*繁中可以輸入 zh 或是 Chinese
*更多指令可以參考 whisper –help 或官方文件查詢。
*更多指令可以參考 whisper –help 或官方文件查詢。
指定用 CPU 解碼成繁中範例:
whisper A2hosting2023.wav --language zh --model small --device cpuA2hosting2023.wav 請換成自己的聲音檔名
本案例 –model 可選較快的 small 或準確率較高但執行較久的 medium,甚至更高的 large,但時間會大幅拉長,有顯卡加速為佳。
指定用 NVDIA 顯示卡 GPU 解碼成繁中範例:
whisper A2hosting2023.wav --language zh --model medium --device cuda| 多語言模型 | 需要顯存(VRAM) | 相對速度(large為基準) |
| base | 1GB+ | 16x |
| small | 2GB+ | 6x |
| medium | 5GB+ | 2x |
| large | 10GB+ | 1x |
如果跑出 torch.cuda.is_available() is False 這個錯誤,代表你必須重新安裝 PyTorch 這個程式成比較新的版本才能用 GPU 解碼。
處理無法使用 NVDIA 顯卡解碼
如果你確定你使用的是 NVDIA 顯卡卻還是出現 torch.cuda.is_available() is False 這個錯誤,那應該是 PyTorch 驅動的問題。
先解除安裝本來的 PyTorch:
pip uninstall torch清除快取:
pip cache purge下載安裝支援CUDA的PyTorch以及CUDA Toolkit:
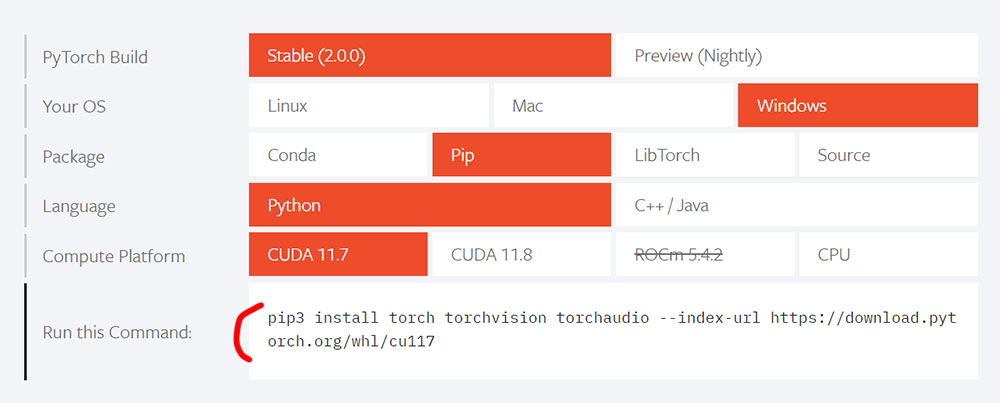
頁面中間可以選擇作業系統,版本等,然後下方會自動產生 pip 指令,複製回來終端機貼上就會安裝
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu117這邊依照顯卡不同支援的 cu11.7、cu11.8 不一定,建議進去後它預設幫你選好的來下載(它系統會偵測),如果不行再重複上面的解除安裝 PyTorch 指令,安裝另一個版本試試看。
這邊指令輸入進去後,應該會要下載1~2GB大小的檔案(在終端機中)
,所以要等一下,如果沒有的話可能表示有問題,我第一次用 cu116 版只要我下載 127MB,結果用完後還是無法用 GPU。
後來再一次解除安裝 PyTorch,換成安裝 117 版,這次就要我下再安裝 2.2 GB 安裝完就可以正常使用了。
安裝好後可以再次下指令執行看看
轉字幕指令(使用gpu加速)
whisper [你的聲音檔名].wav --language zh --model medium --device cuda在改成用 gpu 其實預設都會用 gpu,要用 cpu 跑要寫成以下:
whisper [你的聲音檔名].wav --language zh --model medium --device cpu硬體需求:實機測試 Whisper 翻譯字幕速度&顯卡與CPU性能差異
| 多語言模型 | 需要顯存(VRAM) | 相對速度(large為基準) |
| base | 1GB+ | 16x |
| small | 2GB+ | 6x |
| medium | 5GB+ | 2x |
| large | 10GB+ | 1x |
這是 Whisper 官方給出的顯示卡使用各語言模型所需要的記憶體(VRAM),如果你影片長度不要太長,使用 CPU 直接解也是可以,就直接使用你電腦本身的記憶體(實測不論模型大約都是佔用 10GB)。
只是使用 CPU 要有心理準備產出的時間會非常非常久,來看看我以下實測的數據:
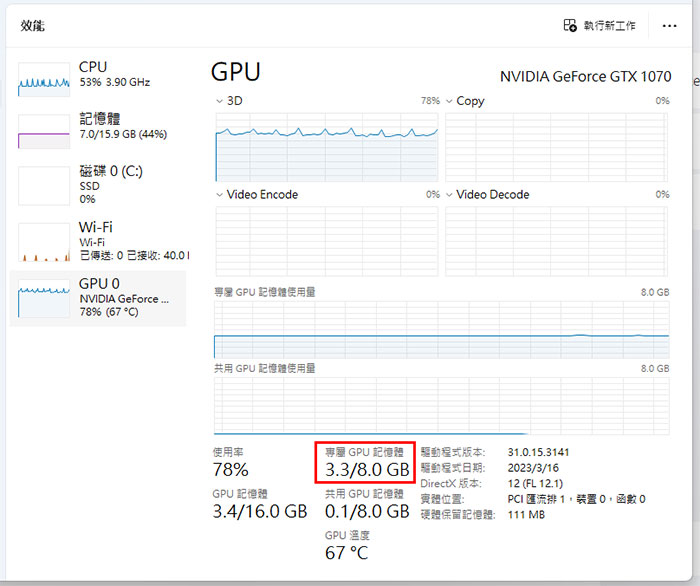
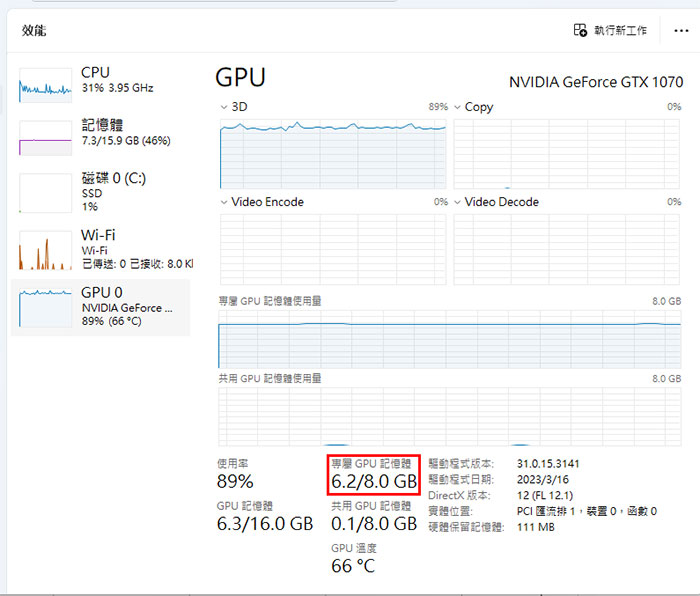
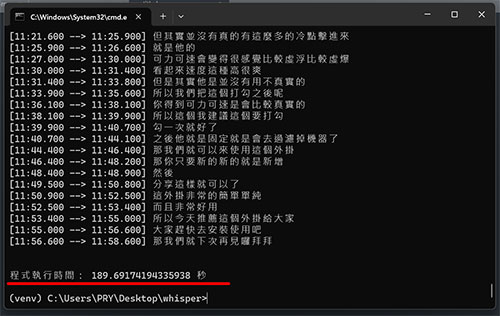
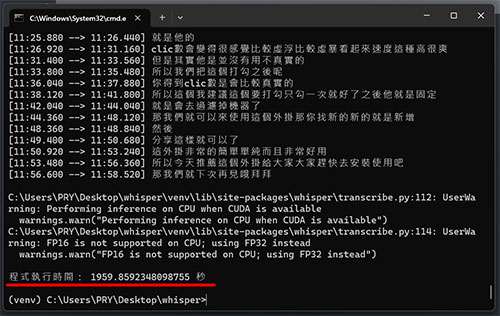
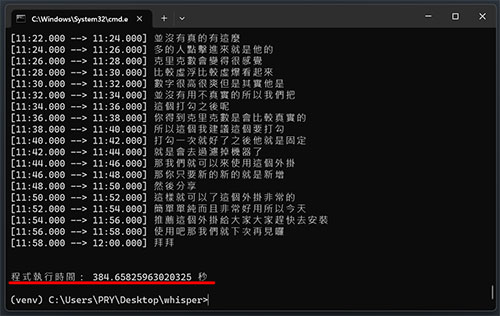
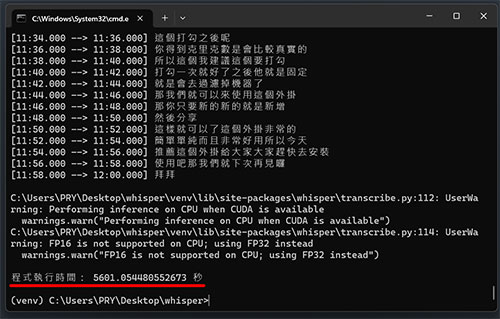
從上數據可以看佔用 VRAM 比官方宣稱的還大一點,因此建議顯卡記憶體越大越好,用 CPU 的話只要電腦記憶體本身夠大(實測幾乎就是 10GB)就沒限制,就是時間久了點,如果可以掛網放著跑倒也是沒關係。
要用哪個語言模型好?差異大嗎?
理論上用最高的準確度越好,我看人實測 Medium 比剪映的準確率平均高上 6%。而 Small 模型則和剪映差異不大。但同樣 Whisper 的 Medium 和 Large 之間,準確率誤差只能再提升不到 1 %。以上都是以繁體中文來做測試的結果。
不要小看 6% 的差距,在上萬字的文字中,6% 差距就可以少更正很多錯字了。且還是直接給繁體中文。
繁體中文或簡體中文字幕?
我用 Whisper 的時候它總給我繁體的翻譯,我很滿意,雖然我也疑惑過為何 zh 能直接代表繁體,直到有人問了我它最近轉換出來都是簡體該怎麼辦?
找了一下資料,Whisper 作者似乎為了簡化指令,只要是中文都是用 zh 或 Chinese 來下指令,無法直接區分繁體或簡體。不過似乎在程式中是有預留這部分的功能的。
但從這篇官方的簡體或繁體討論文章來看,應該只要在指令後方給他一段文字,他會從這段文字使用簡體或繁體來決定使用哪個模型。
$ whisper --language Chinese --model large audio.wav
[00:00.000 --> 00:08.000] 如果他们使用航空的方式运输货物在某些航线上可能要花几天的时间才能卸货和通关
$ whisper --language Chinese --model large audio.wav --initial_prompt "以下是普通話的句子。" # traditional
[00:00.000 --> 00:08.000] 如果他們使用航空的方式運輸貨物,在某些航線上可能要花幾天的時間才能卸貨和通關。
$ whisper --language Chinese --model large audio.wav --initial_prompt "以下是普通话的句子。" # simplified
[00:00.000 --> 00:08.000] 如果他们使用航空的方式运输货物,在某些航线上可能要花几天的时间才能卸货和通关。
關鍵就在於加入這段指令:
--initial_prompt "以下是普通話的句子。"
它似乎會辨別雙引號中的中文是繁體的還是簡體的,來產生字幕。如果你的 Whisper 翻譯的語言不如你意,可以試試。GUI 介面的翻譯我就不知道該怎麼簡繁轉換了。
使用 Whisper GUI 介面:簡單、效能要求更低、速度還更快!
在這裡,所有的學習內容都是免費的。
如果這讓你感到滿意,一杯咖啡能讓我們走得更遠。




嗨!歡迎來到造九 😊 打聲招呼吧!